The cost of 1KB?
Key to good web development practice is to deliver the user experience ‘over the wire’ in as few KB as possible.
For the purpose of clarity, I’m specifically talking about ensuring that HTML (including images), CSS (including images, Data URIs etc) and JavaScript is delivered over the wire to the user in the smallest data size possible.
1. Perfplanet
2. Ilya Grigorik ‘1000 millisecond time to glass’ (PDF)
3. Need something basic about simple front-end optimisations? Here’s a beginner focused rundown of optimisations I wrote about some time back.
Why care?
Less data sent to the user results in faster page loads, this in turn leads to a better user experience and often less cost to the user (less data to download is particularly useful to users on limited bandwidth data plans, typical of mobile handsets).
However, at times it can be hard to convince developers about the importance of good front-end code optimisations and why they are worth concentrating on. There are at least two possible paths of resistance:
Perhaps their build system and deploy process doesn’t include the necessary features to automate as many of the optimisations as possible or point out when things have gone wrong. This then requires (more costly) human intervention.
Perhaps some developers just don’t care. Why on earth would that be the case? I think the answer is simple: because it doesn’t directly affect them.
Perhaps we can address both these possible scenarios?
Who this isn’t for
It’s true that on limited budget projects, there isn’t always the will (by one or more parties) to take the time and money to set up a system to achieve these kind of optimisations.
If you find yourself in that kind of situation, reframing the need to perform front-end code optimisations to clients might help. Brad Frost has written about performance as part of the design process and Tim Kadlec has also written about setting a performance budget too.
But in this instance, I’m less concerned about those scenarios.
Who this is for
Let’s concern ourselves purely with large scale outfits. To exemplify, I’m talking about companies with their own server rooms that count their minimum daily users in the millions.
These are the companies that are really, tangibly, paying for serving their data.
Each time they have to serve a customer with data there is an associated cost. How can we quantify that cost? What does each 1KB they have to serve cost?
Quantifying the cost of 1KB
In simplistic terms how about the yearly cost of serving data divided by the amount of data served in a year (cost / data). This is crude, granted but it gives a basic metric with which to work. The cost of serving data may include the hardware, service costs, support personnel – that’s for you to decide.
This simple calculation can provide the approximate ‘cost of 1KB’ to your company.
Ripples
With the cost of 1KB to your company defined, it’s then possible to consider the cost savings possible by data economies made on the front-end in relation to other numbers.
For example, how many users are being served a day? If 50 KB of data was saved off the page load to every end-user, how much data transfer does this save per day? Per month? Per year?
That’s one set of statistics. But it would also be great to know what that ultimately costs a company. I wrote a (very) crude calculator to churn out some numbers (it’s up on GitHub as a gist so I welcome your improvements). Punch in some big numbers and see how things measure up:
Enter your data
Avoid using decimals or units when you input values
Data savings
Data saved per day: 0
Data saved per week: 0
Data saved per month: 0
Your costs saving
To serve 1KB costs you: 0
Your data economy saves this much per day: 0
Your data economy saves this much per week: 0
Your data economy saves this much per month: 0
Your data economy saves this much per year: 0
Limitations
Let’s be clear. There are many reasons why these results may not be accurate. That little tool is just to provide a finger in the air. Something to get developers who are producing and deploying front-end code that hits millions of users thinking about what optimisations to their code might save.
There’s the distinct possibility that the reality is that such data economies really do make no financial difference (or so little to be irrelevant) when it comes to the cost of serving data. However, what if they do? What if they save the company £10,000 a year, £20,000 a year? More?
Make them care
Possible money savings from data optimisations are all well and good, but we still need to make it affect the developers who need some incentive to be thinking about saving KB in the first place. Here are some obvious riposte’s I could imagine hearing:
“What’s the point, I won’t get the money saved”
If you’re a developer in a large company, it’s not possible to control what management do with the money that gets saved and squirrelled away. All it is possible to do is the right thing. If you feel so badly about your company and what the money gets spent on that you don’t want or care to make possible economies I’d argue it’s time you looked for a new job.
Plus, if you’re a professional being paid to produce front-end code by a company, you should care about this anyway.
“Our company is a multi-national – these savings are a drop in the ocean”
Unless you have worked in a company that is on the fine fiscal line between staying in business or not it’s perhaps difficult to appreciate why these things might matter.
EVERYTHING MATTERS.
Every penny/cent does count.
The money that gets pissed away irresponsibly today is the same money that can keep you getting paid in the future when profits margins are slim. If you are unfortunate enough to find yourself in a situation where you are being laid off and you took no action here, ask yourself – did YOU do everything you could when you could?
Especially when for the most part, many economies can be automated by a build system.
Time for a little less stick and a bit more carrot. How we can we make this more positive for developers? I have some ideas.
Pay review
Before we go here, I’ll re-iterate an earlier point. If you are paid as a professional to produce front-end code for a large company you should care about the economy of the code produced anyway.
However, if just feeling all warm and smug inside and being able to sleep at night isn’t enough, perhaps a further incentive. At set times, most large companies perform pay reviews with employees. Said employees will usually argue why they are due ‘X amount extra’. Well, if they can demonstrate how they have saved their company ‘X’ amount of money in data economies, surely that’s a stronger case to argue their cause? Perhaps this warrants a further riff:
Data economy bonus?
It’s often to the chagrin of developers that sales staff seem to enjoy all the performance related perks. Perhaps a monthly incentive for the developers at the deployment side of things that can demonstrate the largest possible data savings?
How to know what’s happening?
Suppose there’s general buy-in to this whole front-end data-saving business. How can it be measured by a team?
I recently came across a great blog post by Stefan Judis that demonstrated a tool for showing deployment statistics. It provides feedback on each deploy to production.
It can automagically create SVG graphs like this on each deploy:
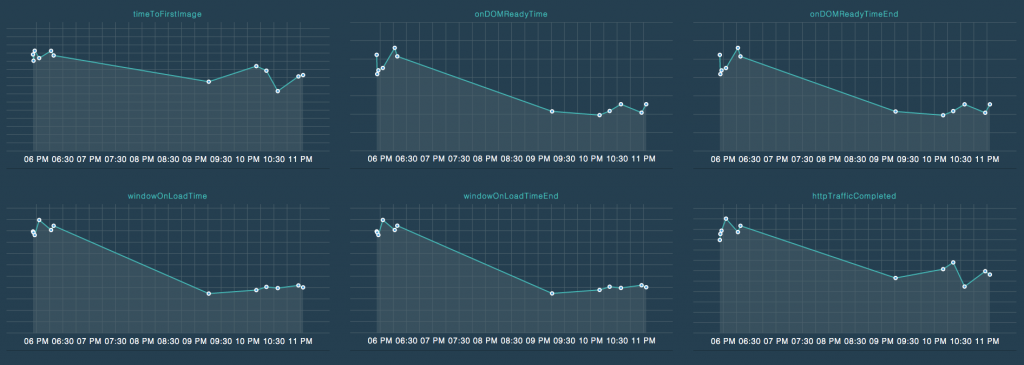
Want to see a full example of the output? Head here: http://stefanjudis.github.io/grunt-phantomas/gruntjs/.
This is based on a Grunt based workflow but even if you aren’t using Grunt, the principal is sound – perhaps just apply the principal to your own stack. On each deploy you get a sparkline. Look at the output – did it go up or down? And by how much? Sudden spike? Time to check that latest deployment.
It makes sense to consider new features. If a new feature (code) is added, things will likely go up but there’s at least a baseline to measure against and then in turn optimise against.
Let the whole team know
When it comes to deployment, it’s important to know how things are going from one deployment version to the next. On large scale operations it’s likely not one person that contributes everything to the deployment so if everyone can see sparklines each time something goes live, maybe that would help?
Have you seen the Panic statusboard? How about something like that on a big screen above the folks involved with deployment with the aforementioned types of statistics displayed? Might even catch a few problems that standard build tests wouldn’t. For example, it’s unlikely that standard tests would catch an oversized Data URI in the CSS but a spike on the sparkline from one deployment to the next would.
Conclusion
I’d be keen to hear how large companies deal with this. Particularly those with large scale deployments. How do they address and encourage gaining optimisations on the front-end? I’d also be keen to know whether or not something as small as a 50KB data saving on the homepage would save a large company any substantial amounts of money over a year?
Thanks for mentioning. 🙂